
Snappy Compression Benchmark on Ethereum's Mainnet Blocks
In a p2p network, nodes share information by sending messages to each other. In the Ethereum p2p network, nodes send blocks, transactions, and many other types of messages. All nodes need to send the data (e.g., blocks) in a format that other nodes can understand. Thus, messages get serialized before being sent over the network. After the data has been serialized, it can be compressed to reduce the network bandwidth consumption and speed up network transfers.
Data Serialization on Ethereum
The most common serialization format is JavaScript Object Notation (JSON), which is generally preferred because of its wide usage, its human-readable format, and its wide support in most of the available languages.
# Ethereum Block example JSON serialized
{"message": {
"slot": "5900800",
"proposer_index": "38712",
"parent_root": "0x1873a84d7ab44903d500b787ef17388d6ba9d280...9c06066e026",
"state_root": "0xbc2f460f05aefdac814543a6f796408c7d6f031...16ae827fa5",
"body":{
...
}
}
However, JSON is too verbose for our purposes. When encoding/serializing any object, JSON writes everything using strings, which makes it human-readable, but it also substantially increases the size of the output file.
Another serialization tool is SSZ. SSZ is a simple serialization tool that aims to be light, while limiting the max-size of each variable. Ethereum uses SSZ to serialize data before sending it across nodes in the network. The following figure shows the differences in size for the same Ethereum blocks when comparing different serialization approaches. In the following figures, we can see the raw bytes size of each block serialized in JSON and in SSZ. In the figure, we can clearly see that JSON serialized blocks take up to twice as much as the SSZ version, demonstrating the benefits of SSZ over JSON.
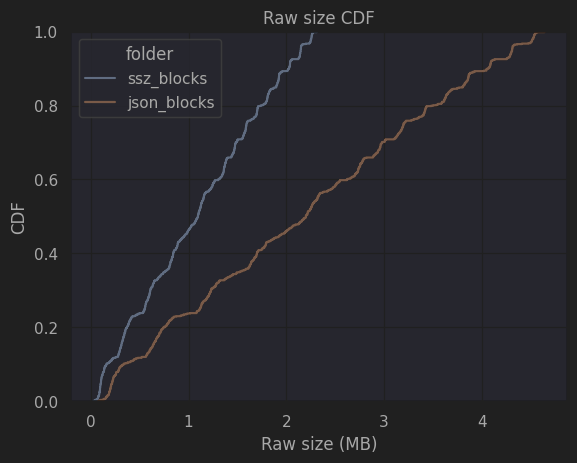 |
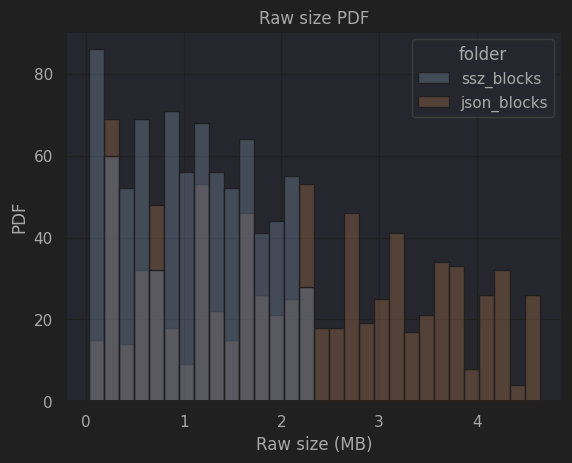 |
|---|---|
| Raw block size (CDF) | Raw block size (PFD) |
Data Compression on Ethereum
After serialization, blocks are compressed to reduce network bandwidth consumption, hence reducing transmission times. To achieve this goal, Ethereum uses Snappy for fast compression, hoping to gain more time in network transmission, than the lost time in compression. More specifically, SSZ is combined with Snappy when sending Blocks, Attestations, and Aggregations.
We performed a short analysis of Snappy years ago, but that was done even before the Beacon chain was launched, so the data used then was not representative of what we see currently on-chain. Therefore, we decided to study the performance of Snappy compression today with real blocks in Mainnet.
Evaluation Setup
It is important to note that blocks of different sizes might have different types of data, thus they might exhibit different behavior when compressed. Therefore, to further enhance our compression benchmark, we used a set of different sized blocks extracted from Mainnet. We used 60 blocks for each size range, except for the last one (2251 KB - 2500 KB) because we did not find more blocks of such size occurring in the last six months.
| Block size range (KB) | Number of samples |
|---|---|
| 0000 - 0250 | 60 |
| 0251 - 0500 | 60 |
| 0501 - 0750 | 60 |
| 0751 - 1000 | 60 |
| 1001 - 1250 | 60 |
| 1251 - 1500 | 60 |
| 1501 - 1750 | 60 |
| 1751 - 2000 | 60 |
| 2001 - 2250 | 60 |
| 2251 - 2500 | 20 |
| Total | 560 |
Compression Speed
The following figure shows the compression time for each of the different block-size ranges. As one would expect, larger blocks need more time to be compressed. However, the time for compressing the data barely exceeds the 5ms on the largest blocks. This demonstrates that Snappy is a library clearly focused on high compression speed.
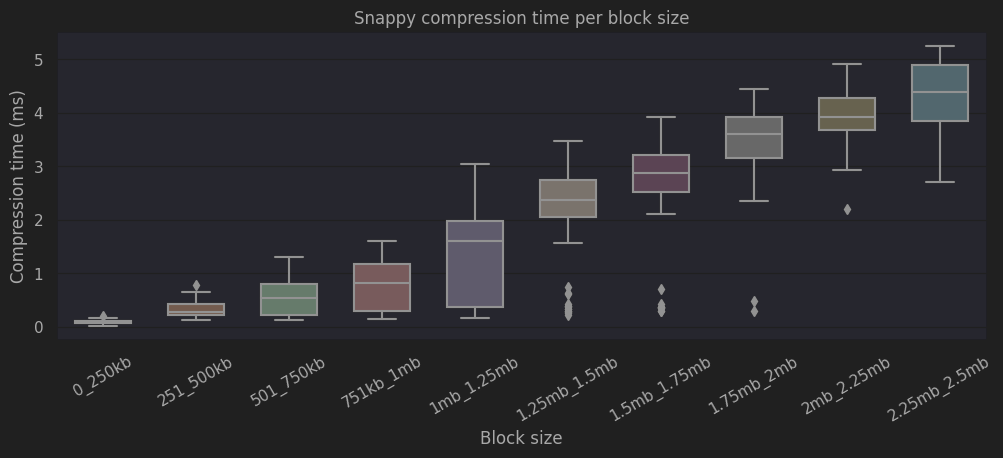 |
|---|
| Compression time for different sized blocks |
In common scenarios, with blocks rounding the 100 KB, Snappy compression time remains under the 1ms. This overhead is close to nothing when we compare it to network latencies that oscillate between 50 and 100 ms.
Decompression Speed
Regarding decompression speed, we can observe that the process takes only half of the compression time, barely reaching 2.5ms for the largest blocks.
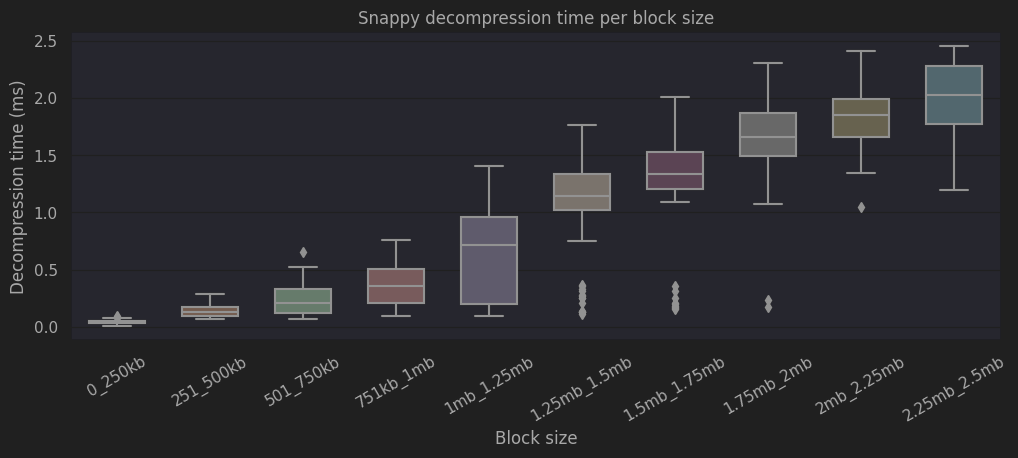 |
|---|
| Decompression speed per block size |
Compression Ratio
As explained previously, compression speed is useless if the compression ratio is zero. In the worst case, nodes will expend between 1-5 ms to compress the block plus 0-2.5 ms to decompress it on arrival, to reach a 1/1 compression ratio. So, is compression really useful? Let's find out.
The following figure shows the CDF of the compression ratio for the different block size ranges. Several things are clearly visible. i) There are 2 blocks that achieve a compression ratio higher than 3, which is a great compression ratio for such compression speed. ii) Over half of the blocks (53.5%) achieve a compression ratio higher than 2. iii) Almost 95% of all the blocks tested, achieve a compression ratio higher than 1.5. Overall, these seem to be quite good results given the short compression times presented above.
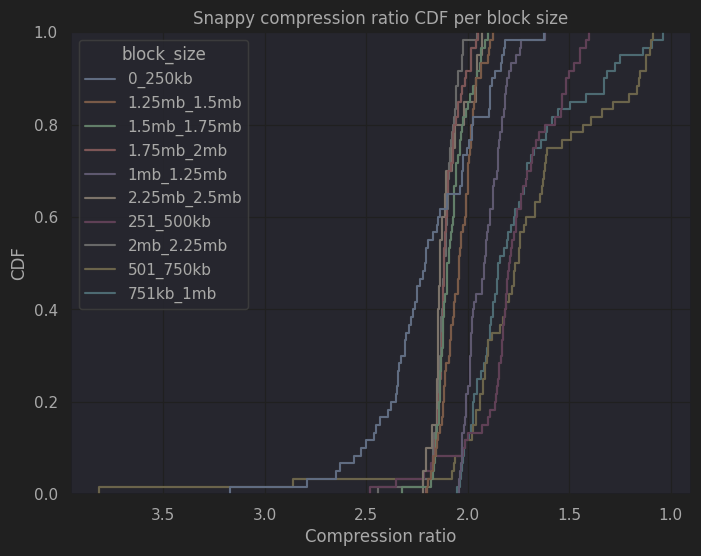 |
|---|
| CDF of the compression ratio per block size |
The next figure shows the quartiles of the compression ratio for the different block size ranges. The first thing we notice is that we see a higher variance for blocks between 0 KB and 1250 KB, which have an approximate median compression ratio of 1.8. Blocks over 1250 KB have a much lower variance but also exhibit a slightly higher compression ratio.
The higher compression ratio could be explained by the fact that to produce such large blocks, the block should have a significant number of zeros. This is related to the cost of CALLDATA. Using CALLDATA to store data on a block, costs 16 gas per byte for non-zero bytes, and 4 gas per byte for zero bytes. The maximum gas used in a block is 30,000,000. Assuming the block is full of non-zero bytes in CALLDATA, the maximum block size would be 30,000,000/16 = 1,875,000 bytes. However, when the data has many zeros (which only cost 4 gas), it is easier to inflate the block size. Thus, it is to expect that large blocks have a significant number of zeros, which Snappy exploits during the compression. In addition, it is virtually impossible to reach such block size using standard transactions. It follows then, that the large majority of big blocks have the same internal structure, which in turn explains the low variance we observe in these results.
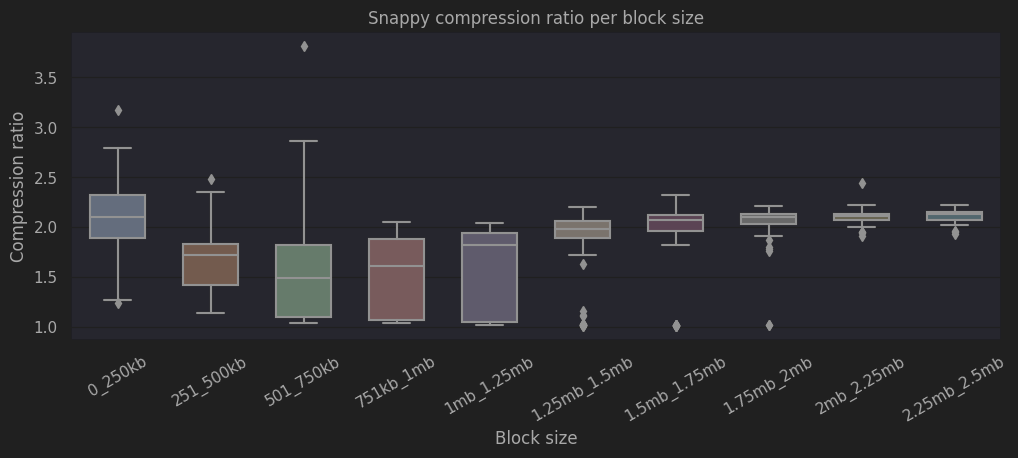 |
|---|
| Compression ratio per block size |
Interestingly, we also observe high compression ratio in small blocks, which can be explained by very small blocks that are almost empty and that are very easy to compress.
Conclusion
These results show that Snappy takes only a few milliseconds to compress and decompress blocks in Ethereum. The large majority of blocks in Ethereum have a size of about 100 KB, and this study shows that using Snappy those blocks will be reduced to half their size when sent over the network. It is worth highlighting that big blocks also reach good compression ratios, which is good news for EIP-4844.